Kubernetes administrators may see new vulnerability scanner findings on June 1, 2026, even on clusters that are already patched. The Kubernetes Security Response Committee says it will correct CVE records for several older unfixed issues that previously included inaccurate fixed-version data.
This is not a normal “upgrade to version X and close the ticket” situation. It is a scanner-triage and configuration-risk problem. Hosting providers, SaaS teams, agencies running customer workloads, and homelab operators should be ready to explain why the findings appear, which clusters are affected, and what configuration reviews are needed.
What Kubernetes is changing
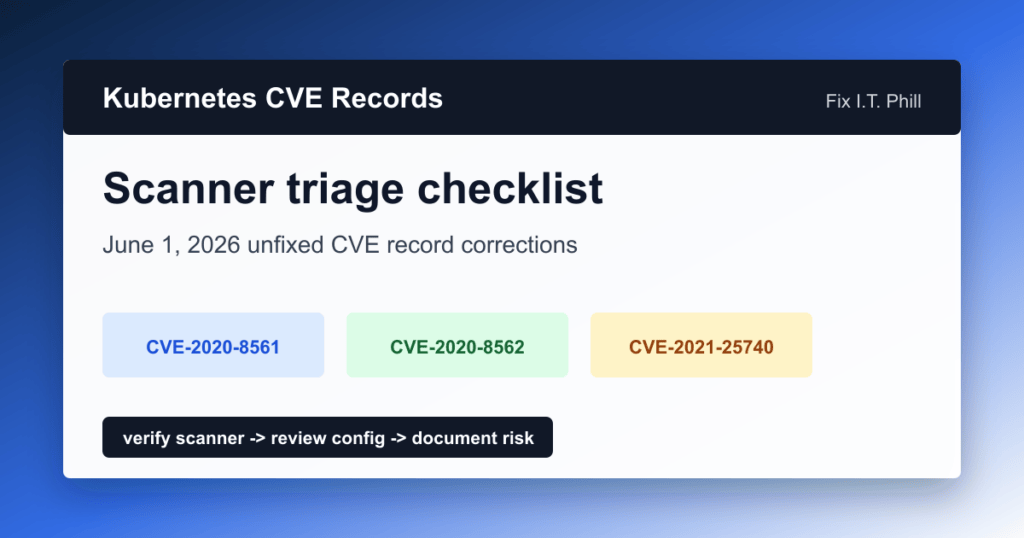
The official Kubernetes blog says the CVE records for these older issues will be corrected on June 1, 2026:
- CVE-2020-8561: webhook redirect risk in kube-apiserver.
- CVE-2020-8562: Kubernetes API server proxy DNS timing risk.
- CVE-2021-25740: Endpoint and EndpointSlice permissions that can allow cross-namespace forwarding.
Kubernetes says these issues remain unfixed because they are architectural design trade-offs, not simple missing patches. The practical result: scanners may start reporting them after the records are corrected, and teams should be ready with a documented response.
Do not treat every alert as a patch failure
When the scanner finding appears, do not immediately assume the cluster missed a Kubernetes update. First confirm whether the scanner is reporting one of the corrected CVE records. Then decide whether the finding reflects a real configuration concern in your cluster, a managed-control-plane responsibility, or a risk you already mitigated with RBAC, admission-control, DNS, webhook, or network restrictions.
Cluster-admin checklist
- Record the scanner name, scan date, Kubernetes version, cluster type, cloud/provider, and exact CVE IDs reported.
- Confirm whether the finding is one of the Kubernetes June 1 record corrections.
- Separate self-managed control planes from managed Kubernetes. Some controls may be owned by the cloud or platform provider.
- Review admission webhook ownership, RBAC roles, broad edit permissions, service and ingress controls, and DNS behavior against your cluster threat model.
- Check whether existing hardening baselines already address the risky behavior.
- Document what is mitigated, what is accepted risk, what requires provider guidance, and what still needs a maintenance window.
Hosting and tenant-isolation notes
For hosting providers and agencies running multi-tenant workloads, prioritize clusters where customers can influence ingress, services, admission webhook behavior, or namespace-level routing. These findings are more important in shared or semi-shared clusters than in a tightly controlled single-tenant environment.
If you use managed Kubernetes, open the provider’s security guidance before changing production settings. If you self-manage the control plane, plan changes the same way you would plan any cluster-security maintenance: back up etcd where applicable, use a staging cluster first, keep rollback notes, and watch controllers and workloads after the change.
What to tell customers or leadership
A useful status note is: “Kubernetes corrected older CVE records on June 1, 2026, so scanners may now report risks that were previously hidden by inaccurate fixed-version metadata. We are reviewing affected clusters for configuration exposure, managed-provider responsibility, and tenant-isolation impact. This is not automatically evidence that a cluster missed a current patch.”
Safe verification
- Compare scanner findings with the official Kubernetes CVE feed and Kubernetes blog post.
- Review RBAC and admission-control ownership in an admin-approved way.
- Confirm whether broad edit roles or customer-managed namespace settings are present.
- Review network, DNS, ingress, service, and webhook controls without testing against third-party systems.
- Record the conclusion in the ticket: patch needed, configuration change needed, provider-owned, mitigated, or accepted risk.
Fix I.T. Phill recommendation
Treat this as a risk-documentation exercise with real security value. A scanner ticket that cannot be cleared by upgrading is still worth handling. The win is to identify whether the cluster’s configuration, tenancy model, provider boundary, and RBAC posture make the issue relevant, then document the mitigation or acceptance clearly enough that the same alert does not burn admin time every week.
Related Fix I.T. Phill guides
- Docker Desktop CVE-2026-5843: Model Runner Patch Guide
- NGINX CVE-2026-42945 and CVE-2026-9256 Patch Guide
- PHP May 2026 Security Releases: Hosting Update Checklist